I took the opportunity to upgrade the ember-mqttjs support to Ember v4 for refactoring the addons tests. During last EmberFest (which happened in Rome on Sept. 30 and Oct. 1, 2021) I listened to a lot of brilliant talks. One of them caught my attention because it dealt with the testing topic and in particular of mocks and stubs.
Gonçalo Morais dove into this argument with some stunning hints during his talk “Mock & Roll” that opened my minds and let me wondering on how to improve my mqtt ember addon tests.
After some experiments with the mock-socket library I realized that this tool was not anymore mantained and combining some searchs into the Sinon.JS documentation I found a way to stub the MQTT.js dependency faking the connect method.
This method returns a client and triggers some events that are useful to understand the mqtt connection status. Joining the replace and fake methods from Sinon.JS I found a way to simulate the MQTT.js connect method behavior returning a client with the necessary methods and triggering the needed events.
As you can see next on the code sample attached to this post I need to add some tricks to the joke, because for example the connect event needs to be trigger after a delay while the fake client declares an event handler that must to be there when the event is fired. Or for example the subscribe and publish methods need to call a callback with the correct parameters.
Once I discovered this tricks the tests runs correctly and I can assume that my code is working fine relying on the MQTT.js client to be properly tested.
Code sample
This is the example for the connect test but you can find the whole code into the addon repository:
import { module, test } from 'qunit';
import { setupTest } from 'ember-qunit';
import sinon from 'sinon';
import mqttjs from 'mqtt/dist/mqtt';
import Service from '@ember/service';
import Evented from '@ember/object/evented';
import { later } from '@ember/runloop';
class MqttServiceStub extends Service.extend(Evented) {}
module('Unit | Service | mqtt', function (hooks) {
let mqttHost = 'ws://localhost:8883';
let mqttTopic = 'presence';
let mqttMessage = 'Hello';
let mqttServiceStub;
setupTest(hooks);
hooks.afterEach(() => {
sinon.restore();
});
// ...
//Testing mqtt connect
test('mqtt connect success', async function (assert) {
let service = this.owner.lookup('service:mqtt');
let done = assert.async();
assert.expect(3);
mqttServiceStub = new MqttServiceStub();
sinon.replace(
mqttjs,
'connect',
sinon.fake(() => {
later(() => {
mqttServiceStub.trigger('connect');
}, 100);
return {
on: (sEvent) => {
mqttServiceStub.on(sEvent, () => {
if (sEvent === 'connect') {
return service.onConnect();
}
});
},
};
})
);
try {
service.on('mqtt-connected', () => {
assert.ok(true);
});
await service.connect(mqttHost);
assert.ok(service);
assert.ok(service.isConnected);
} catch {
assert.ok(false);
assert.ok(false);
assert.ok(false);
} finally {
done();
}
});
If you notice some errors or you need more informations about the code I’m happy to hear from you. Reach me through my contact page.



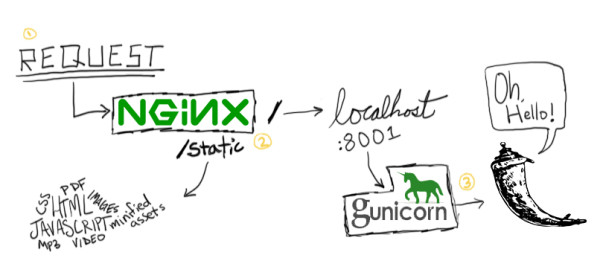
 Oggi scrivo di una piccola scoperta fatta giocando con
Oggi scrivo di una piccola scoperta fatta giocando con